)


Advancing AI Research and Innovation with Sovereign AI Cloud Infrastructure
KInIT is an independent research institute focused on advancing artificial intelligence through a combination of cutting-edge research and real-world impact. Our mission is to develop trustworthy, human-centric AI technologies and to support their effective adoption in practice. Positioned at the intersection of academia and industry, KInIT plays a key role in strengthening the AI ecosystem in Slovakia and contributing to broader European efforts in building sovereign and competitive AI capabilities.
Researching the Limits and Capabilities of Modern AI
At KInIT, we focus on some of the most pressing challenges in contemporary AI research. A major part of our work is dedicated to generative AI and large language models, where we investigate not only their performance but also their limitations and risks. This includes evaluating how such models behave across different tasks, how they perform in low-resource languages such as Slovak, how they can be adapted efficiently to domain-specific use cases and different tasks, and how they can be aligned to reflect requirements on specific behavior (e.g., not to generate harmful content).
An important aspect of this research is understanding the societal implications of AI systems. For example, we study the ability of generative models to produce disinformation, as well as methods for detecting and mitigating such risks. At the same time, we explore efficient adaptation techniques, including various forms of fine-tuning and parameter-efficient learning, enabling organisations to deploy advanced AI systems without prohibitive computational costs.
From Research to Real-World Impact
Research at KInIT is primarily application-oriented. By researching and pushing the frontiers of various state-of-the-art methods, we build deep expertise that can be transferred into practice through collaborations with industry and public sector partners. Our research is applied across a range of domains, including natural language processing, multimodal AI, disinformation analysis, recommender systems, predictive modeling or predictions related to financial data.
This research and its applications require not only strong methodological foundations but also the ability to experiment at scale, validate solutions, and deploy them in suitable environments.
Infrastructure as the Foundation of the AI Lifecycle
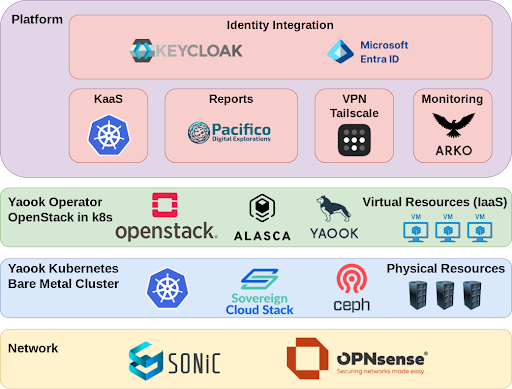
To support this broad spectrum of activities, KInIT needs a comprehensive and versatile computing infrastructure based on open technologies. The infrastructure will serve as a foundation for the entire AI lifecycle – from data processing and experimentation to large-scale model training and deployment.
Unlike traditional HPC environments that are primarily optimized for batch processing, our infrastructure is designed to support both research experimentation and production-grade AI services. Built on an OpenStack-based architecture, it allows researchers to flexibly allocate resources, run complex workloads, and deploy services in isolated environments, including isolated on-demand Kubernetes clusters.
This enables a seamless workflow in which models can be developed, tested, scaled, and deployed within a single integrated platform. Researchers can start with small-scale experiments, iterate rapidly, and then scale their workloads to more powerful configurations as needed.
Enabling Cutting-Edge AI Research
The computational capabilities of the infrastructure allow us to explore state-of-the-art and emerging AI paradigms. This includes training and evaluating large-scale generative models, experimenting with multimodal and multi-agent systems, and investigating advanced approaches such as reinforcement learning or physics-informed models.
In addition, the infrastructure supports research into explainability and mechanistic interpretability, helping us better understand how complex AI systems operate internally. This is an important component of developing trustworthy AI systems, as it enables deeper insights into model behavior, decision-making processes, and potential failure modes.
The ability to run computationally intensive experiments locally is essential for maintaining research agility and independence, while also allowing us to prepare and optimize workloads before scaling them to external high-performance computing systems when needed (e.g., national or European HPC infrastructure).
Bridging Research and Deployment
One of the key strengths of our infrastructure is its versatility. It is not limited to experimentation but is equally suited for deploying and operating AI systems in production-like environments. This includes hosting machine learning models, serving APIs, and running complex AI pipelines that integrate multiple components.
The platform’s design provides adequate infrastructural support for complex distributed setups like multi-agent systems, enabling experimentation with advanced AI architectures while also providing the reliability and scalability required for real-world applications. This makes it possible to bridge the gap between research prototypes and deployable solutions, accelerating the transfer of knowledge into practice.
Requirements and their Prioritization
Requirements were defined and prioritized as follows:
- No Vendor Lock-in
- Maximize computational performance with focus on GPU-accelerated compute nodes and combined VRAM
- Fast network, at least 200 Gbit/s
- Fast storage, roughly 1 PB (raw capacity), extensible in the future
- HW and SW infrastructure suitable for AI both executing extensive experiments (data processing, training, evaluation) and reliable deployment of complex models and solutions
No Vendor Lock-in
dNation has won a tender for cluster installation. In the following text we will describe how they have been addressing requirements above.
No vendor lock-in requirement consists of following sub-requirements:
- All source code is available under some OSS license
- Installation procedure is fully documented
- GitOps used for installation and operations is available as well as both source code and its documentation
As the cornerstone of whole solution, OpenStack by OpenInfra has been chosen to provide:
- True sovereignty without any vendor lock-in, all sourced code is available under Apache 2.0 license
- Infrastructure as a Service (IaaS)
- Ability to transparently handle HW and network failures
- Isolation between AI workloads, including network traffic
![]()
![]()
Yaook distribution of OpenStack has been used for seamless installation and operations. Yaook has been developed by ALASCA (Association for Operational, Open Cloud Infrastructures e.V.) non-profit consortium.
![]() Sovereign Cloud Stack (SCS) non-profit is a European initiative that creates an open, transparent and vendor-neutral cloud ecosystem. Part of its activities covered by Forum SCS-Standards are to define, document and develop standards and certifications to ensure expected level of quality of sovereign clusters. Yaook is an SCS certified solution.
Sovereign Cloud Stack (SCS) non-profit is a European initiative that creates an open, transparent and vendor-neutral cloud ecosystem. Part of its activities covered by Forum SCS-Standards are to define, document and develop standards and certifications to ensure expected level of quality of sovereign clusters. Yaook is an SCS certified solution.
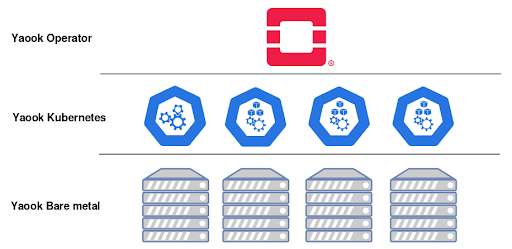
Yaook runs OpenStack containerized within Kubernetes running on bare metal nodes:
Yaook’s architecture allows:
- Automatically transfer a set of bare metal machines to an operational OpenStack cluster
- Release management – all OpenStack components are tested together and then atomically released as a single package using standard Kubernetes deploy mechanisms
Maximum performance of accelerated nodes
![]() When designing the infrastructure, the primary objective was to maximize computational performance within the available budget, with a particular focus on GPU-accelerated computing to support modern AI workloads. Given the rapid evolution of artificial intelligence (especially in areas such as large language models and multimodal systems) it was essential to prioritize high-performance, high-memory GPU resources.
When designing the infrastructure, the primary objective was to maximize computational performance within the available budget, with a particular focus on GPU-accelerated computing to support modern AI workloads. Given the rapid evolution of artificial intelligence (especially in areas such as large language models and multimodal systems) it was essential to prioritize high-performance, high-memory GPU resources.
![]() Supermicro was selected as it enabled an optimal balance between cost and performance. Within the given budget constraints, it was possible to deploy four accelerated compute nodes equipped with a total of 5× NVIDIA H200 NVL (141 GB) GPUs and 20× NVIDIA RTX Pro 6000 (96 GB) GPUs, providing substantial computational capacity and memory footprint for both training and inference workloads.
Supermicro was selected as it enabled an optimal balance between cost and performance. Within the given budget constraints, it was possible to deploy four accelerated compute nodes equipped with a total of 5× NVIDIA H200 NVL (141 GB) GPUs and 20× NVIDIA RTX Pro 6000 (96 GB) GPUs, providing substantial computational capacity and memory footprint for both training and inference workloads.
At the same time, the infrastructure has been designed with future scalability in mind. In the near future, the system is planned to be extended with additional accelerated nodes featuring potentially over 2 TB of GPU memory, allowing the infrastructure to address the increasing complexity and scale of emerging AI models and advanced training approaches.
Fast network
To provide fast network, following leaf-spine network topology has been used:
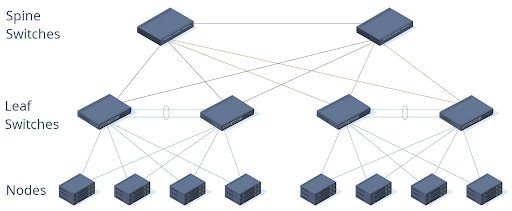
Each cable from a node to leaf switch has 100 Gbps network speed. Two cables are combined on a software level and combine a bond with 200 Gbps network speed.
Leaf switches are connected on layer-2 to virtual chassis using MLAG protocol while communication with spine switches is performed on layer-3.
Failure of one cable from a bond causes that another cable is transparently used. This way both improved speed and resiliency is achieved as there is no single point of failure.
Fast storage
![]() Multiple storage types with 1 PB raw capacity have been used to support various storage needs:
Multiple storage types with 1 PB raw capacity have been used to support various storage needs:
- Local NVMe storage
- Each AI node has 3 fast NVMe PCIe 5.0 SSDs configured in RAID-5 to provide fast storage for locally ran AI workload
- Redundant network CEPH storage
- 3 nodes configured using CEPH to provide fast, redundant and scalable storage for results of AI computations
- Each AI node is connected to this storage via 200 Gbps network
- Cold storage
- Two nodes providing backup storage via NFS
While the CEPH-based storage is used for I/O-intensive workloads and scenarios requiring a high level of data protection, it was not economically feasible to scale this redundant architecture to several hundreds of terabytes. Therefore, an additional high-capacity NVMe-based warm storage layer was incorporated as a single-node, scalable solution.
This layer is designed for workloads that still require high throughput and low latency, but where there is a higher tolerance for potential data loss, for example in intermediate data processing, large-scale experimentation, or reproducible training pipelines. In this way, the infrastructure achieves an efficient balance, reserving highly resilient storage for critical data, while enabling cost-effective scaling for performance-demanding but less critical workloads.
Kubernetes as a Service (KaaS)
Most planned AI computations take place inside the Kubernetes cluster, so KaaS has been implemented using the Cluster API approach. To ensure non-reduced performance, Kubernetes PODs have direct (non-layered) access to the GPU hardware.
Firewall
![]() The cluster is protected from the Internet by the OPNsense – open source, FreeBSD-based firewall and routing software.
The cluster is protected from the Internet by the OPNsense – open source, FreeBSD-based firewall and routing software.
Secure VPN Access
![]() Access to the cluster and virtual machines running on it are protected by VPN provided by Tailscale zero Trust identity-based connectivity platform.
Access to the cluster and virtual machines running on it are protected by VPN provided by Tailscale zero Trust identity-based connectivity platform.
Monitoring

![]() ALASCA Arko is a standardized platform for efficient monitoring of hybrid cloud infrastructures. We are using it for constant cluster monitoring, alerting and supporting Day 2 operations.
ALASCA Arko is a standardized platform for efficient monitoring of hybrid cloud infrastructures. We are using it for constant cluster monitoring, alerting and supporting Day 2 operations.
Arko follows these design principles:
- Intuitive: Green, orange and red colors signaling whether your action is needed
- Relevant information only: Provides only metrics relevant for area of interest
- Hierarchical (drill-down): Details needed? Just click on it.
Integration with Microsoft Entra ID
![]() To achieve integration between KInIT’s cloud-based identity provider, OpenStack and Kubernetes, Keycloak identity and access management solution has been used.
To achieve integration between KInIT’s cloud-based identity provider, OpenStack and Kubernetes, Keycloak identity and access management solution has been used.
MS Entra ID is used as the primary source of information so KInIT doesn’t have to change its usual identity workflow.
Reports of Cluster Usage
![]() OpenStack doesn’t contain sufficient built-in reporting capabilities, so we used RacStack – A Billing Dashboard For OpenStack developed by Pacifico Digital Explorations.
OpenStack doesn’t contain sufficient built-in reporting capabilities, so we used RacStack – A Billing Dashboard For OpenStack developed by Pacifico Digital Explorations.
If you have any questions
Do not hesitate to contact us:
- For AI research related questions: [email protected]
- For Infrastructure related questions: [email protected]
- The KInIT Case Study: Sovereign AI Cloud - April 16, 2026



